

Votre application tourne sur le cloud. Elle dépend d’une base de données managée, d’une API d’envoi d’emails, d’un CDN, d’un service d’authentification… peut-être d’un modèle d’IA hébergé.
Chacun de ces services affiche un SLA (Service Level Agreement) : un engagement contractuel de disponibilité.
Votre fournisseur vous promet 99,9 %. Vous signez. Tout va bien.
Sauf que… 99,9 %, c’est 43 minutes de panne autorisées par mois. Pile pendant le Black Friday, un lundi matin, ou la démo client.
Et dans le contrat ? C’est écrit noir sur blanc : c’est normal, pas de compensation.
Le SLA, c’est un peu comme la garantie de votre voiture :
- « Couvert 5 ans » sonne bien…
- …jusqu’à ce que vous lisiez les exclusions : usure normale, mauvaise utilisation, pièces d’origine uniquement
- Et il faut envoyer un recommandé sous 15 jours
Cet article, c’est le guide pour lire les petites lignes, avec des vrais chiffres, des vrais contrats, et des outils pour calculer vous-même.
SLA, SLO, SLI : posons le vocabulaire
Trois acronymes, trois rôles différents. Ils sont souvent confondus, mais c’est important de les distinguer avant d’aller plus loin.
| Terme | Ce que c’est | Exemple |
|---|---|---|
| SLI (Service Level Indicator) | La métrique brute mesurée par vos outils de monitoring | « Taux d’erreur HTTP 5xx sur les 5 dernières minutes » |
| SLO (Service Level Objective) | L’objectif interne que vous vous fixez | « Notre taux de succès doit rester au-dessus de 99,95 % sur 30 jours » |
| SLA (Service Level Agreement) | Le contrat avec votre client ou fournisseur, avec des conséquences financières | « 99,9 % de disponibilité mensuelle, sinon crédits » |
En résumé : le SLI mesure, le SLO fixe l’objectif, le SLA engage juridiquement.
En pratique, votre SLO devrait toujours être plus ambitieux que votre SLA. Si vous promettez 99,9 % à vos clients, visez 99,95 % en interne. La marge entre les deux, c’est votre filet de sécurité.
Le vrai coût d’un « nine »
On mesure la disponibilité en « nines » : 99 %, 99,9 %, 99,99 %…
Chaque nine en plus divise le temps de panne par 10. Simple, non ?
Sauf que la perception est trompeuse. La différence entre 99 % et 99,9 % ? Plus de 6 heures de panne en moins par mois. Entre 99,9 % et 99,99 % ? On passe de 43 minutes à 4 minutes.
Un e-commerce à 100 000 EUR de CA/jour, concentré sur 6 heures de pic. 43 minutes de panne sur ce créneau = potentiellement 10 000 EUR de pertes, sans compter les paniers abandonnés.
Pour mieux visualiser l’impact, voici un calculateur interactif. Déplacez le curseur pour changer le pourcentage de disponibilité et voir le temps de panne correspondant par jour, mois et année. C’est bidirectionnel : vous pouvez aussi modifier directement un temps d’arrêt pour retrouver le pourcentage associé.
Quel impact sur votre disponibilité ?
Outil interactif, testez avec vos chiffresDes pannes, ça arrive (vraiment)
Ce n’est pas de la théorie. Voici quelques incidents récents :
-
AWS us-east-1, 20 octobre 2025 : une race condition dans le système DNS de DynamoDB supprime par erreur des enregistrements DNS actifs1. Plus de 15 heures de panne. Netflix, Slack, Snapchat, Coinbase, Expedia hors ligne. 3 500+ entreprises impactées dans 60+ pays, plus de 4 millions de signalements en 2 heures.
-
Cloudflare, 18 novembre 2025 : un bug dans le système de Bot Management génère un fichier de configuration surdimensionné, propagé à tout le réseau. Résultat : les serveurs crashent en cascade2. ~2 heures de panne mondiale. X, ChatGPT, Spotify, Anthropic, Canva, League of Legends inaccessibles.
-
Cloudflare, 5 décembre 2025 : rebelote un mois plus tard. Une modification du parsing des requêtes HTTP provoque une panne affectant 28 % du trafic mondial3 pendant 25 minutes.
-
Google Cloud, 12 juin 2025 : un bug de type null pointer met hors service plus de 50 services pendant 7 heures4. Spotify, Gmail, Fitbit touchés.
-
OVHcloud Strasbourg, 10 mars 2021 : un incendie détruit le datacenter SBG2. 3,6 millions de sites hors ligne, des données définitivement perdues car les sauvegardes étaient dans le même bâtiment. OVH condamné à 145 000 EUR de dommages5.
Ces incidents étaient tous couverts par des SLA. Les crédits remboursés ? Une fraction de la facture mensuelle.
Entre août 2024 et août 2025, AWS, Azure et Google Cloud ont cumulé plus de 100 pannes de service6. Ce n’est pas l’exception, c’est la norme.
Les status pages : votre premier réflexe
Comment savoir si votre fournisseur est en panne en ce moment ?
C’est le rôle de la status page : une page publique où le fournisseur affiche l’état de ses services en temps réel :
C’est aussi votre source de preuve si vous devez réclamer des crédits SLA.
La status page ne reflète que ce que le fournisseur accepte de montrer. Pendant l’incident AWS de décembre 2021, le dashboard de santé AWS était lui-même inaccessible.
Ce que le SLA ne vous dit pas
Le pourcentage affiché est séduisant. Mais il cache l’essentiel.
La définition très restrictive de « panne »
Chez Google Cloud (Cloud Run functions)7, l’indisponibilité n’est comptée que si le taux d’erreur dépasse 10 % des requêtes sur une période de minutes consécutives.
Concrètement :
- Un timeout isolé ? Pas compté.
- Un pic de latence de 30 secondes ? Pas compté.
- Une intermittence de moins d’une minute ? Pas comptée.
Votre utilisateur, lui, a vu une page blanche. 🤷
Le « taux d’erreur » lui-même est défini de façon restrictive : c’est le ratio requêtes en erreur / total des tentatives, avec un minimum de 100 requêtes pour que la mesure compte.
Votre fonction Cloud Run reçoit 80 requêtes dans la minute, et 70 échouent (87 % d’erreurs). Du point de vue du SLA ? Ça ne compte pas. Il fallait au moins 100 requêtes pour que la minute soit évaluée. Résultat : le service est considéré comme « disponible à 100 % » sur cette période, alors que vos utilisateurs ont eu 87 % d’échecs.

Quand le service « fonctionne »… mais que ça ne marche pas
Votre API renvoie des erreurs en rafale. Vos utilisateurs voient des pages blanches. Mais côté fournisseur ? Tout est vert. Le service est « disponible ».
Comment c’est possible ?
Parce qu’il existe toute une catégorie d’erreurs que le fournisseur ne considère pas comme de l’indisponibilité. Ce sont des erreurs « de votre fait », même si en pratique elles sont souvent liées à des limites de la plateforme.
Le throttling (limitation de débit) : c’est le cas le plus courant en situation de charge. Chaque service cloud impose des quotas : un nombre max de requêtes par seconde, par minute, par compte. Quand vous dépassez ce quota, le service vous répond 429 Too Many Requests (« trop de requêtes »). Il ne plante pas, il vous freine volontairement. C’est comme un péage qui ferme des voies aux heures de pointe : l’autoroute « fonctionne », c’est juste que vous ne pouvez plus y accéder.
Votre API d’envoi d’emails (Mailjet, SendGrid…) autorise 100 appels/seconde. Votre campagne marketing déclenche 500 appels/seconde. Résultat : 80 % des requêtes sont rejetées en 429. Côté SLA ? Tout va bien, le service « fonctionne ». Côté utilisateur ? Les emails de confirmation de commande ne partent pas.
Mais le throttling n’est pas le seul angle mort :
400 Bad Request: payload trop gros, requête mal formée, paramètre manquant. Le fournisseur considère que c’est votre code qui est en cause- Cold starts : sur les fonctions serverless (Lambda, Cloud Functions…), la première requête après une période d’inactivité peut prendre plusieurs secondes le temps que l’environnement démarre. Ce n’est pas une erreur au sens du SLA, mais pour l’utilisateur qui attend, c’est du temps perdu
- Latence dégradée : le service répond, mais en 5 secondes au lieu de 200 ms. Tant qu’il répond, il est « disponible »
Du point de vue de l’utilisateur final, le résultat est le même : ça ne marche pas.
Si vous avez déjà testé la montée en charge de vos APIs, vous avez peut-être rencontré ces limites. Cf. notre article sur les tests de charge réalistes.
Un SLA de 100 %, ça existe ?
AWS Route 538 affiche 100 % de disponibilité.
Impressionnant… sauf que ça exclut :
- Les erreurs de propagation DNS
- Les mauvaises configurations
- Les pannes régionales
En gros, le service est « disponible » tant que leurs serveurs répondent, pas forcément que votre domaine fonctionne.

La maintenance planifiée ne compte pas
Même les maintenances d’urgence. Chez Azure9, les fenêtres planifiées ne comptent pas dans le calcul de disponibilité.
Le SLA mesure ce que le fournisseur décide de mesurer, pas ce que vos utilisateurs vivent.
Le piège du SLA composite
C’est le calcul que personne ne fait, et qui change tout.
Votre application ne dépend jamais d’un seul service. Elle passe par une API Gateway, une base de données, un cache, un CDN, un service d’emails…
Et les SLA, ça se multiplie :
SLA système = SLA₁ × SLA₂ × SLA₃ × …
Prenons une architecture e-commerce classique. Chaque service affiche 99,9 % de disponibilité :
- API Gateway + Service API + Base de données, 3 maillons en série : 0,999 × 0,999 × 0,999 = 99,7 % → 2 h 10 de panne autorisée/mois (au lieu de 43 min pour un seul service)
- CDN + API Gateway + Service API + Base de données + Stockage objet, 5 maillons : 0,999⁵ = 99,5 % → 3 h 36 de panne/mois
Vous pensiez avoir 43 minutes de downtime autorisé ? Avec une architecture standard à 5 dépendances, c’est plus de 3 heures de panne cumulée par mois.
La bonne nouvelle : la redondance inverse la tendance. Deux réplicas d’une base à 99,9 % donnent un SLA de 99,9999 % pour ce maillon.
Le compromis :
- Chaque réplica = une instance à payer
- De la synchronisation à gérer
- Un load balancer en plus dans la chaîne (avec son propre SLA…)
Pour le voir par vous-même, voici un simulateur de SLA composite. Ajoutez les services de votre architecture réelle (API Gateway, base de données, cache, emails…) et observez le SLA global chuter. Vous pouvez basculer un service en mode HA (haute disponibilité) pour simuler l’ajout d’un réplica et voir comment la redondance améliore le résultat.
Quel SLA pour votre architecture ?
Outil interactif, configurez votre architectureSi vous engagez un SLA auprès de vos propres clients, ce calcul est votre point de départ. Promettez toujours moins que votre SLA composite réel, c’est votre marge de manoeuvre quand un fournisseur a un incident.
Les compensations : le diable dans les détails
Si le SLA n’est pas tenu, vous êtes remboursé ?
En théorie, oui. En pratique, c’est plus nuancé.
| Fournisseur | SLA | Crédits | Conditions |
|---|---|---|---|
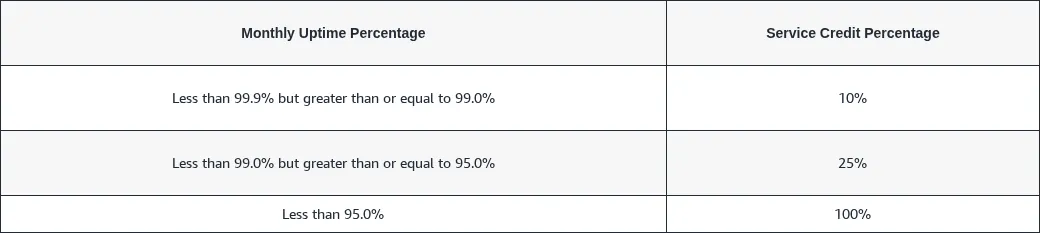
| AWS S3 | 99,9 % | 10 % → 25 % → 100 % | Via AWS Support |
| Azure Blob Storage | 99,9 % | 10 % → 25 % | Throttling exclu |
| Google Cloud Run | 99,95 % | 10 % → 25 % → 50 % | Max 50 %, sous 30 jours |
| Clever Cloud | 99,9 % | Formule : indispo% × facture annuelle × 2 | Annuel, max 10 % de R |
| Mailjet API | 99,99 % | 5 % par tranche de 30 min | Sous 30 jours, max 50 % |
La formule de Clever Cloud mérite une explication : T est le taux d’indisponibilité (minutes de panne ÷ minutes du mois), R la redevance annuelle (facture mensuelle × 12). Ainsi, pour 9h de panne sur un mois avec 500 €/mois de consommation : T = 540 / 43 200 ≈ 1,25 %, R = 6 000 €, pénalité = 1,25 % × 6 000 × 2 = 150 €, plafonnée à 10 % de R, soit 600 €.
Le point commun ? C’est à vous de réclamer. Personne ne viendra vous rembourser spontanément :
- Chez AWS, il faut ouvrir un ticket au Support
- Chez Clever Cloud, fournir un ticket avec preuves d’indisponibilité sous 60 jours
- Chez Mailjet, réclamer sous 30 jours avec preuve d’impact
- Pas de réclamation = pas de crédit
Et les montants sont plafonnés : souvent 50 % ou 100 % de la facture du mois, pas de votre perte réelle.
Le prix d’un meilleur SLA
Les crédits SLA existent, mais encore faut-il pouvoir les réclamer. Chaque fournisseur propose une échelle de plans support, du gratuit au premium, avec des prix qui varient considérablement.
Chez les hyperscalers, ces plans ne modifient pas le pourcentage de SLA : ils améliorent le support (temps de réponse, interlocuteur dédié) et donc votre capacité à réclamer des crédits.
| Fournisseur | Plan | Coût | Réponse (cas critique) |
|---|---|---|---|
| AWS | Basic | Gratuit | Self-service uniquement |
| Business+ | Dès 29 $/mois (3–9 % facture) | < 30 min | |
| Enterprise | Dès 5 000 $/mois (3–10 % facture) | < 15 min, TAM dédié | |
| Azure | Basic | Gratuit | Self-service uniquement |
| Developer | 29 $/mois | Heures ouvrées | |
| Standard | 100 $/mois | < 1h, 24/7 | |
| Pro Direct | 1 000 $/mois | < 1h, escalade dédiée | |
| Google Cloud | Basic | Gratuit | Self-service uniquement |
| Standard | 29 $/mois (ou 3 % facture) | 4h, 5j/7 | |
| Enhanced | Dès 100 $/mois (ou 10 % facture) | < 1h, 24/7 | |
| Premium | Dès 15 000 $/mois (ou 10 % facture) | < 15 min, TAM dédié | |
| Clever Cloud | Standard | Inclus | Ticket, heures ouvrées |
| Premium | 1,8× conso + 490 € HT/mois | ≤ 15 min, 24/7 |
Sans plan payant, pas de support technique. Avec le plan Basic (gratuit) d’AWS, Azure ou Google Cloud, vous n’avez accès qu’au self-service et au support facturation. Pour ouvrir un ticket technique (nécessaire pour réclamer un crédit SLA), il faut au minimum un plan payant (dès ~29 $/mois).
Attention au “temps de réponse”. Les durées affichées dans le tableau (15 min, 1h…) correspondent à l’initial response time, c’est-à-dire le premier accusé de réception de votre ticket, pas la résolution du problème. Entre le « nous avons bien reçu votre demande » et le correctif effectif, il peut s’écouler des heures, voire des jours. Aucun fournisseur ne s’engage contractuellement sur un délai de résolution.
Mensuel ou annuel : la période de mesure change tout
La majorité des hyperscalers (AWS, Azure, Google Cloud) mesurent la disponibilité au mois. Conséquence : une panne massive le 30 du mois ? Le compteur repart à zéro le 1er. L’incident est « oublié ».
Clever Cloud fait exception avec un SLA annuel (99,9 % en standard, 99,99 % en offre Premium). L’offre Premium change aussi la formule de pénalité (50× plus favorable) et relève le plafond à 1 mois de consommation, contre 10 % de la redevance annuelle en standard. La différence sur la période de mesure est significative :
- SLA mensuel (AWS, Azure, GCP) : chaque mois est évalué indépendamment. 6 petites pannes réparties sur 6 mois ? Chaque mois peut rester au-dessus du seuil → aucun crédit, même si le cumul est important
- SLA annuel (Clever Cloud) : le temps d’indisponibilité s’accumule sur 12 mois. Les mêmes 6 pannes finissent par faire exploser le budget annuel → un crédit est déclenché
Le simulateur de remboursement en bas d’article compare les deux modèles. Testez avec des pannes fréquentes mais courtes : vous verrez que seul le SLA annuel de Clever Cloud déclenche un crédit.
AWS S3 affiche une durabilité de 99,999999999 % (11 nines). C’est la probabilité de ne pas perdre vos données, pas la disponibilité pour y accéder. Deux métriques très différentes.
Première confrontation avec le sujet ? L’essentiel à retenir de cette section : ne comptez jamais sur les crédits SLA pour couvrir vos pertes réelles. Intégrez ce risque dans votre budget et votre architecture, pas dans vos espoirs de remboursement.
L’error budget : piloter au lieu de subir
Le concept vient du Google SRE Book10 et change la façon dont on gère la fiabilité.
Jusqu’ici, le SLO est un chiffre passif : « on vise 99,95 % ». L’error budget le rend actionnable. Le principe : si votre SLO est 99,95 %, vous acceptez 0,05 % d’indisponibilité. Ce 0,05 %, c’est votre budget. Sur un mois de 30 jours, ça représente ~22 minutes.
Chaque incident, chaque déploiement raté, chaque latence dégradée consomme ce budget. Quand il reste du budget, vous avez de la marge pour innover. Quand il s’épuise, c’est le signal pour consolider.
Le calcul
La formule est simple :
Error budget = (1 - SLO) × période de mesure
| SLO | Budget / mois | Budget / trimestre |
|---|---|---|
| 99,9 % | 43 min | 2 h 10 |
| 99,95 % | 22 min | 1 h 05 |
| 99,99 % | 4 min 19 s | 13 min |
Plus votre SLO est ambitieux, plus votre budget est serré. C’est un arbitrage conscient : un SLO à 99,99 % vous laisse moins de 5 minutes de marge par mois. Chaque déploiement devient un risque calculé.
Le circuit de décision
L’intérêt de l’error budget, c’est qu’il transforme un chiffre abstrait en règle de décision concrète pour les équipes :
- Budget confortable (> 50 % restant) : on shippe, on expérimente, on prend des risques calculés
- Budget serré (< 30 % restant) : on gèle les déploiements non-critiques, on se concentre sur la stabilité
- Budget épuisé : post-mortem obligatoire, gel total des déploiements, plan d’action avant de reprendre
Votre SLO est 99,95 %, soit 22 minutes de budget ce mois-ci. Lundi, un incident réseau consomme 8 minutes. Mercredi, un déploiement raté en ajoute 10. Il reste 4 minutes de marge. La refonte du panier est prête, mais la déployer maintenant risque de vider le budget. Décision : on attend le mois prochain.
Sans error budget, cette décision serait un débat d’opinion entre la PM qui veut livrer et l’ops qui veut stabiliser. Avec le budget, c’est un fait : il reste 4 minutes, on ne prend pas le risque.
Comment le piloter au quotidien
L’error budget ne se suit pas dans un tableur. Les équipes SRE s’appuient sur des outils de monitoring qui calculent le burn rate (la vitesse à laquelle le budget se consomme) en temps réel :
- Datadog SLO Tracking : définition de SLO avec alertes automatiques sur le burn rate
- Prometheus + Grafana : stack open source, idéal pour commencer sans budget outillage
- Honeycomb Burn Alerts : alertes prédictives qui préviennent avant l’épuisement du budget
Le burn rate répond a une question simple : « à ce rythme, dans combien de temps le budget sera épuisé ? ». Si la réponse est « dans 3 jours » alors qu’on est le 10 du mois, il y a un problème structurel à adresser, pas juste un incident à résoudre.
Si vous n’avez pas encore d’outillage, commencez par Prometheus + Grafana : c’est gratuit et ça couvre 80 % des besoins. L’important n’est pas l’outil, c’est de rendre le budget visible pour toute l’équipe.
Au final, l’error budget transforme le SLO d’un chiffre passif en outil de décision quotidien qui aligne les équipes produit et ops sur un fait partagé, pas sur une intuition.
Promettre un SLA à votre client
Si c’est vous qui devez vous engager, retournez le problème :
- Listez votre chaîne critique : tous les services dont dépend votre produit
- Calculez votre SLA composite : multipliez les SLA de chaque maillon
- Gardez une marge : votre chaîne donne 99,7 % ? Engagez-vous sur 99,5 %. Vous aurez besoin de cette marge pour les incidents non couverts par les SLA fournisseurs
- Définissez vos exclusions : maintenance planifiée, force majeure, mauvais usage. Ce sont les mêmes leviers que vos fournisseurs utilisent
Le SLA que vous promettez ne peut jamais être meilleur que votre maillon le plus faible, sauf si vous investissez dans la redondance pour le renforcer.
Simulez vous-même : combien serez-vous remboursé ?
Maintenant que vous connaissez les exclusions, les formules de calcul et les pièges du SLA composite, testez avec vos propres chiffres. Ajustez la durée de la panne et votre facture cloud pour voir combien chaque fournisseur vous rembourserait, et comparez avec vos pertes réelles.
Combien rembourse votre SLA ?
Outil interactif, simulez vos remboursements| AWS | Azure | Google Cloud | Clever Cloud | |
|---|---|---|---|---|
| Erreurs serveur (5xx)? | ||||
| Indisponibilité totale? | ||||
| Latence dégradée (lenteurs)? | ||||
| Throttling / rate limiting (429)? | ||||
| Cold starts? | ||||
| Maintenance planifiée? | ||||
| Multi-AZ / multi-zone requis? | ||||
| Tier gratuit / shared? | ||||
| Réseau internet (tiers)? | ||||
| Maintenance client? |
TL;DR
Un SLA, ce n’est ni une assurance tous risques, ni un argument marketing à prendre au premier degré. C’est un engagement minimal, borné par des conditions que personne ne lit.
Ce qu’il faut retenir :
- SLI mesure, SLO fixe l’objectif, SLA engage juridiquement
- 99,9 % = 43 min de panne/mois, et ça arrive (cf. AWS, OVH, Cloudflare)
- Le SLA ne couvre pas tout : throttling, cold starts, latence, maintenance planifiée
- Les SLA se multiplient entre eux : 5 services à 99,9 % = 99,5 % réel
- Les compensations sont à réclamer, plafonnées, et ne couvrent pas vos pertes
- L’error budget transforme le SLO en outil de décision quotidien
- Surveillez les status pages de vos fournisseurs
Les SLA n’engagent que ceux qui les écoutent.
Et maintenant ?
Selon où vous en êtes :
- Vous n’avez pas encore de SLO ? Commencez par instrumenter vos SLI : taux d’erreur, latence P95, disponibilité. Sans mesure, pas d’objectif.
- Vous avez des SLO mais pas de SLA composite ? Listez vos dépendances, multipliez les SLA, et comparez avec ce que vous promettez à vos clients. Le calculateur ci-dessus est là pour ça.
- Vous engagez des SLA clients ? Mettez en place un error budget et une politique de gel des déploiements. C’est ce qui transforme un chiffre sur un contrat en outil de pilotage quotidien.
SLA composite, error budget, SLO internes : on aide les équipes tech à poser les bons chiffres et à les piloter au quotidien. Parlons-en.
Footnotes
-
AWS Outage Analysis, October 20, 2025 - ThousandEyes ↩
-
Cloudflare incident on November 18, 2025 - Cloudflare Blog ↩
-
Cloudflare incident on December 5, 2025 - Cloudflare Blog ↩
-
Google Cloud outage disrupts over 50 services globally for over 7 hours - NetworkWorld ↩
-
Incendie SBG2 Strasbourg : OVH condamné à verser plus de 100 000 EUR - Le Monde Informatique ↩
-
Major cloud outages 2024-2025 - IncidentHub ↩
-
Google Cloud Run functions SLA - Google Cloud ↩
-
Amazon Route 53 SLA - AWS ↩
-
Azure SLA for Online Services - Microsoft ↩
-
Service Level Objectives - Google SRE Book ↩
